El Comité Español de Matemáticas, CEMat, promovió a mediados de marzo la iniciativa Acción Matemática contra el Coronavirus para poner a disposición de las autoridades la capacidad de análisis y de modelización de la comunidad matemática española, por si fuera útil para analizar, comprender y actuar ante la emergencia que estábamos sufriendo con la pandemia covid-19. El Gobierno español se hizo eco del ofrecimiento y desde finales de marzo está recibiendo predicciones a corto plazo de las variables de mayor interés en la expansión del virus, tanto globales de toda España, como desagregadas por comunidades autónomas.
A la iniciativa del CEMat respondieron investigadores de toda España y se puso en marcha un predictor colaborativo para realizar predicciones de las variables en un horizonte entre uno y siete días. Las predicciones se realizan a partir de combinaciones optimizadas de predicciones de diferentes modelos y algoritmos compartidos entre todos los colaboradores, lo cual minimiza los errores de una predicción aislada. Todos los datos aportados son centralizados y tratados en el Departamento de Computación e Inteligencia Artificial de la Universidad de la Coruña (https://covid19.citic.udc.es).
La gráfica siguiente muestra un ejemplo de la predicción del número de infectados (considerando los positivos por cualquier test) que efectuó el predictor colaborativo y los datos reales:
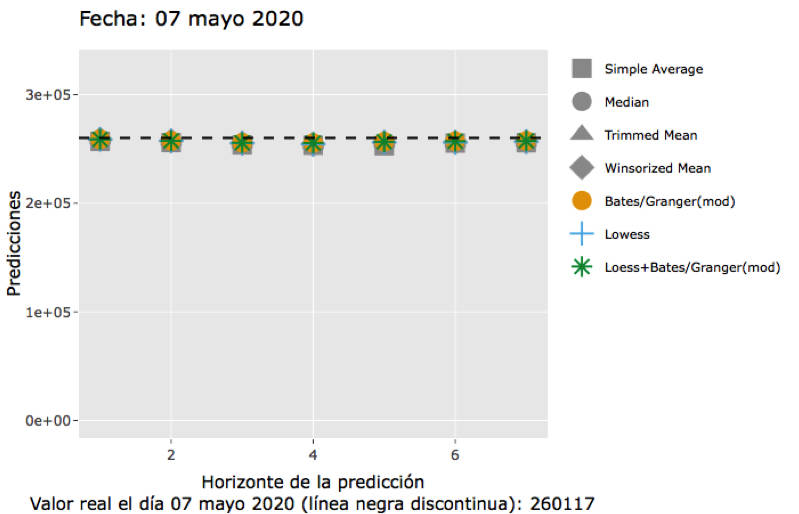
Nuestra aportación al llamamiento del CEMat consistió en la estimación de las variables: infectados, recuperados y fallecidos por la covid-19 en España, mediante un modelo SIRD (https://vicentmartinez.weebly.com/my-work.html) que habíamos tratado en cuarto curso del grado en Matemática Computacional dentro de la asignatura de Modelización Matemática. El modelo SIRD utilizado considera cuatro grupos de personas:
- S (susceptibles), son las personas que pueden ser contagiadas.
- I (infectados), son las personas que se hallan contagiadas.
- R (recuperados), son las personas que han pasado la enfermedad.
- D (fallecidos), conjunto de personas fallecidas.
Las variables están relacionadas dentro de un sistema no lineal de ecuaciones diferenciales, que no mostraremos para no alarmar al lector no matemático.
Para ajustar un modelo SIRD que aproxime los valores conocidos, se toman como valores de contorno el número de susceptibles tanto al empezar como al terminar la epidemia. Obviamente, este último dato no lo conocemos cuando estamos inmersos en la evolución de la epidemia, lo elegimos de manera que mejor ajustan los datos ya observados.
A continuación mostramos algunas predicciones realizadas con nuestro modelo. En la gráfica siguiente se representan los resultados obtenidos hasta el 23 de abril:
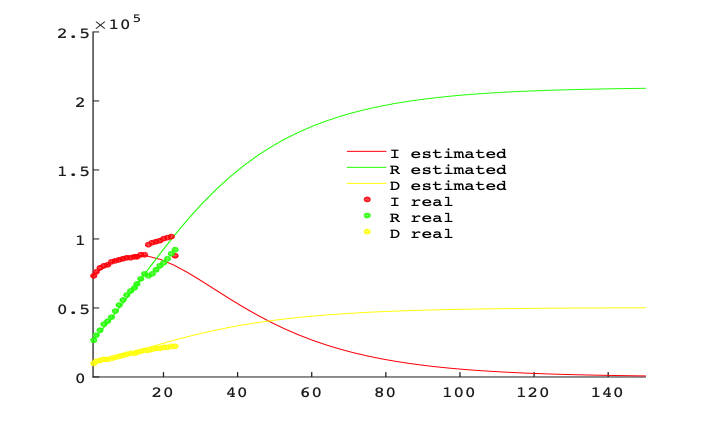 Durante el periodo (13-23 abril), el Gobierno de España reporta un incremento en la cantidad de todo tipo de tests realizados, lo cual desajusta en gran medida los parámetros considerados. Siguiendo el criterio del Gobierno, nosotros nos decantamos por considerar solamente los positivos por PCR (técnica Polymerase Chain Reaction) y modelizar los infectados que pueden obtenerse con el test PCR. Es conveniente matizar que los resultados están condicionados por el número de análisis realizados, que son los que proporcionan el número de infectados, el número de altas médicas (en muchas ocasiones los enfermos siguen su convalecencia en sus domicilios debido a la saturación de los hospitales) y a la efectividad de los tratamientos.
Durante el periodo (13-23 abril), el Gobierno de España reporta un incremento en la cantidad de todo tipo de tests realizados, lo cual desajusta en gran medida los parámetros considerados. Siguiendo el criterio del Gobierno, nosotros nos decantamos por considerar solamente los positivos por PCR (técnica Polymerase Chain Reaction) y modelizar los infectados que pueden obtenerse con el test PCR. Es conveniente matizar que los resultados están condicionados por el número de análisis realizados, que son los que proporcionan el número de infectados, el número de altas médicas (en muchas ocasiones los enfermos siguen su convalecencia en sus domicilios debido a la saturación de los hospitales) y a la efectividad de los tratamientos.
Una representación más fidedigna del comportamiento de la epidemia es representar a trozos su evolución, es decir, ir cambiando los parámetros a medida que las condiciones van cambiando. Si tomando en cada caso los parámetros que mejor se ajustan a los condicionantes impuestos, se puede observar un comportamiento global del modelo adecuado. La siguiente figura muestra el ajuste del modelo SIRD a trozos (a fecha 2 de mayo) para representar las variables más importantes (infectados activos y fallecidos) considerando los cambios de condiciones en la evolución de la epidemia. Puede observarse que los datos de desfase (13-23 abril) es cuando hubo una cierta disfunción en los datos oficiales suministrados:
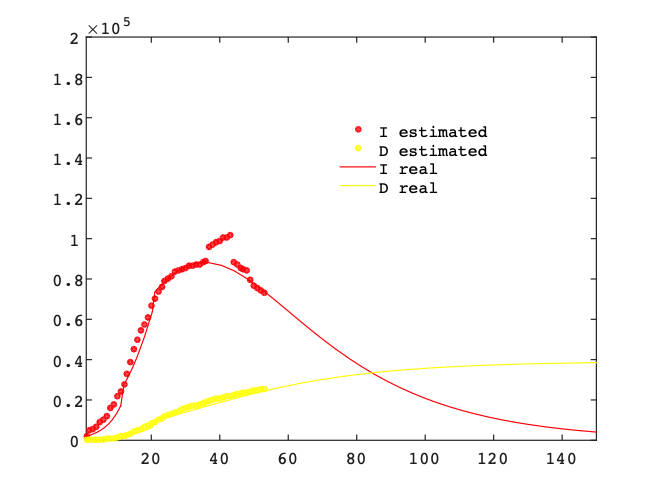 Si solamente se hubiesen considerado los positivos por test PCR la modelización hubiese sido correcta. Esto nos da una idea de la importancia que tiene la calidad de los datos que se consideran. Un dato relevante es que el número de fallecidos tiende a situarse alrededor de 38.000 personas. Es importante recordar que esta cifra es una estimación a día de hoy, la cifra puede disminuir si se mejoran los tratamientos y puede aumentar si se producen rebrotes de la epidemia.
Si solamente se hubiesen considerado los positivos por test PCR la modelización hubiese sido correcta. Esto nos da una idea de la importancia que tiene la calidad de los datos que se consideran. Un dato relevante es que el número de fallecidos tiende a situarse alrededor de 38.000 personas. Es importante recordar que esta cifra es una estimación a día de hoy, la cifra puede disminuir si se mejoran los tratamientos y puede aumentar si se producen rebrotes de la epidemia.
Los modelos se elaboran de acuerdo con los datos recogidos bajo unas determinadas condiciones que, como hemos visto a lo largo del desarrollo de la epidemia, son cambiantes. El número de análisis de diagnóstico no son iguales todos los días, los tratamientos poco a poco resultan más eficaces y las condiciones en los hospitales han ido mejorando. Además, la contabilidad de los datos lleva algunos días de retraso, se comunican al día siguiente de su recogida y el virus tiene un periodo de incubación entre diez y quince días. Si tenemos en cuenta estos condicionantes, las estimaciones realizadas describen en gran medida la evolución de la epidemia.
En días posteriores a la finalización de este estudio es esperable que la epidemia vaya remitiendo, siempre que se mantengan las medidas de aislamiento e higiene adecuadas. Un cambio en las condiciones podría producir repuntes en el número de infectados y la evolución podría tomar, a fecha de hoy, un camino incierto.
Vicente Martínez García, el autor, es catedrático de Matemática Aplicada de la UJI

 Vicente Martínez García, el autor, es catedrático de Matemática Aplicada de la UJI.
Vicente Martínez García, el autor, es catedrático de Matemática Aplicada de la UJI.

